Kubernetes (K8S)
简介
Kubernetes这个词来自希腊语,意思是“舵手”或“领航员”,K8S是Kubernetes的缩写。
Kubernetes是google的容器编排工具Borg的开源版本,google在2014年将其开源,实际上Kubernetes也是应用全生命周期管理的工具。
通过Kubernetes,可以实现大规模容器集群的的自动化部署,自动扩缩容,维护等。
Kubernetes可以运行在物理机或虚拟机上。
特点
可移植:支持公有云,私有云,混合云,多重云
可扩展:模块化,插件化,可挂载,可组合
自动化:自动部署,自动重启,自动复制,自动扩展/收缩
应用生命周期管理步骤
创建集群
部署应用
DEMO
https://kubernetes.io/docs/tutorials/kubernetes-basics/deploy-app/deploy-interactive/
查看应用
发布应用
扩展应用
更新应用
为什么使用容器?
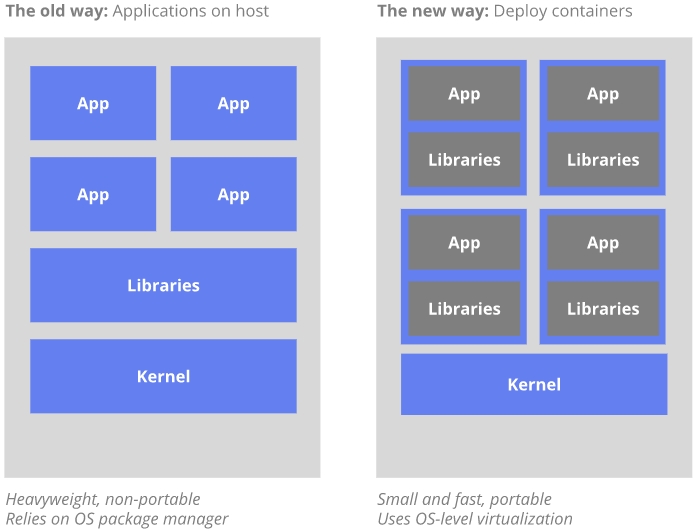
传统方式,应用的运行,配置,管理,所有的生命周期和操作系统绑定,但这样做不利于应用的升级,回滚等。
当然也可以通过虚拟机来实现,但虚拟机非常重。
通过容器来部署应用,容器之间互相隔离,容器与底层硬件和操作系统是解耦的,占用资源少,部署快,每个应用被打包为一个容器镜像。
容器的优势:
快速创建/部署应用:与虚拟机相比,容器镜像的创建更加容易。
持续开发、集成和部署:提供可靠,频繁,简单的容器镜像创建/部署/回滚(容器镜像不可变)
开发与运行相分离
开发,测试与生产环境一致
云平台或其它操作系统:容器镜像可以在RHEL,Ubuntu,CentOS等其它任何环境运行
松耦合(Loosely coupled),分布式,弹性,微服务化:应用程序分为更小的、独立的部件
资源隔离
资源利用:更高效
概念
Cluster
Cluster(集群)是计算、存储和网络资源的集合。
最简单的cluster可以只有一台主机,即是master也是node。
Master
Master是Cluster的大脑,主要负责调度,即决定应用放在哪里运行。
master可以是物理机或虚拟机。
注意:
- 为了高可用,可以有多个master
Node
Node的职责是运行容器应用,node由master管理,node负责监控并汇报容器的状态,并根据master的要求管理容器的生命周期。
node可以是物理机或虚拟机。
Namespace
Namespace可以将一个物理的cluster划分为多个逻辑的cluster,每个逻辑的cluster就是一个namespace。
不同的namespace里的资源是完全隔离的。
Kubernetes默认创建了两个namespace:
- default:创建资源时如果不指定namespace,默认放在这里
- kube-system:K8S系统自己创建的资源,放在这里。
Pod (微服务)
pod是一个逻辑概念,pod是Kubernetes中可创建/部署的最小单位(pod是kubernetes的原子调度单位,因此一个pod中的容器都应该在同一个节点上),每个pod是应用的一个实例
一个Pod封装了如下内容:
- 一个应用容器(也可以有多个容器)
- 存储资源
- 独立的网络IP
- 管理控制容器运行方式的策略选项
注意:
- 容器的本质是进程
- pod类似于进程组
注意:
- docker是pod中的常见运行时(runtime),pod也支持其他的运行时
- 在单个pod中管理多个容器是相对高级的用法
Pod提供两种共享资源:网络,存储
网络:
- 每个pod分配一个独立的IP
- Pod中的每个容器共享网络命名空间(namespace),包括IP和端口
- Pod内的容器可以使用localhost互相通信
存储:
- Pod内所有的容器可以访问共享存储(shared volumes)
- volumes还用于Pod中的数据持久化
举例,如下图这个pod包含File Puller,Web Server两个容器,共享一个存储volume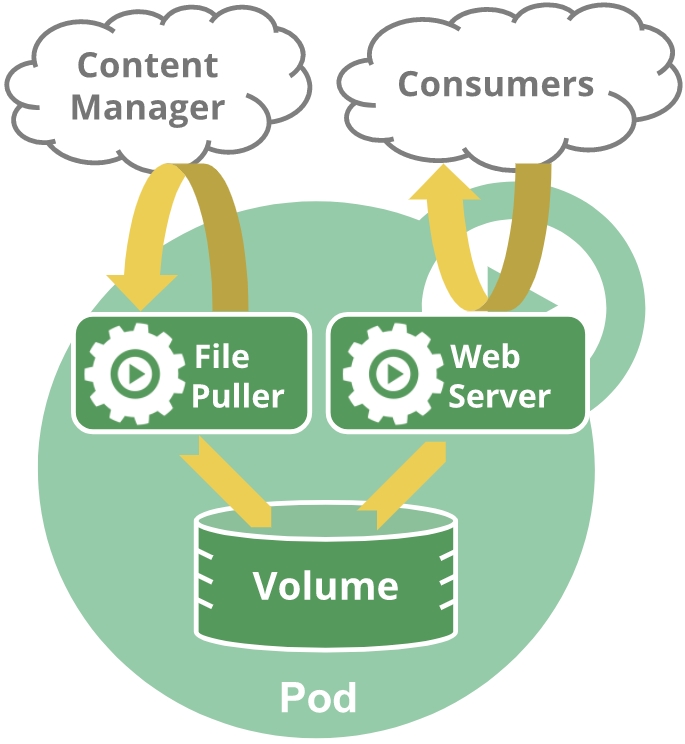
注意:
- 重启pod和重启容器不是一回事,pod只提供容器的运行环境并保持容器的运行状态,容器重启并不会导致pod的重启
上面说到pod是一个逻辑概念,pod实际上是共享了资源的一组容器,主要是共享了网络和存储。
pod在k8s中的实现需要有一个中间容器,叫做infra容器,infra容器永远被第一个创建,然后其他容器和infra容器关联在一起。
Infra容器使用的是一个特殊的镜像k8s.gcr.io/pause,pause镜像由汇编编写,Infra容器永远处于暂停状态。
pod的生命周期和Infra容器的生命周期一致,因此重启pod和重启容器不是一回事。

上图为k8s中的pause镜像
创建一个pod的yaml配置文件,如下
1 | apiVersion: v1 |
可以利用yaml语法工具,如 Link,用以保证生成的yaml文件格式正确
校验通过,格式正确
校验未通过,spec的值有问题,不能出现null
创建pod
1 | kubectl create -f pod_nginx.yaml |
注意:
- 建议在每个节点将镜像拉到本地,否则每次创建pod时找不到本地镜像都会尝试连线下载
- 默认情况下,master节点不会参与pod的部署
查看pod的状态
1 | [root@ol75k8sn2 ~]# kubectl get pods |
查看pod的更多的状态信息,包括IP,node等;如下IP:192.168.43.70是K8S内部网络IP,在每个节点上都可以ping通,IP的取值范围由初始化master节点时kubeadm init的--pod-network-cidr参数来定义
1 | [root@ol75k8sn2 ~]# kubectl get pods -o wide |
获得pod的详细信息
1 | kubectl describe pods nginx |
最后通过curl测试一下nginx的是否运行1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26[root@ol75k8sn2 ~]# curl 192.168.43.70
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
现在在K8S的节点上可以访问内部网络的pod网段192.168.43.*,但外部还不可以
删除pod
1 | [root@ol75k8sn2 ~]# kubectl delete pod nginx |
或
1 | [root@ol75k8sn1 ~]# kubectl delete -f pod_nginx.yml |
注意:
- pod一般不会直接使用,而是通过deployment来管理使用
Controller
Kubernetes可以通过controller创建和管理pod,提供副本管理、滚动升级、集群级别的自愈能力。简单的说就是,有几个副本,在什么样的node上运行。
pod的生命周期管理:当pod被创建后,会被kubernetes调度到node上,直到pod的进程终止、被删除、因为缺少资源被驱逐、node出现故障
Pod模板:
控制器(controller)通过模板来创建pod,对模板的修改不会影响已创建的pod
根据作用的不同,有多种controller
ReplicaSet
用来实现pod的多副本管理,来实现pod的高可用。因此即使只有一个pod副本,也应该用replicaset来管理。比如pod挂了,自动在合适的节点上启动一个pod。pod副本的数量不够了,自动增加一个pod。
注意:
- 上一代的ReplicationController已经不推荐使用
- ReplicaSet包含ReplicationController的所有功能,主要区别是:
- ReplicationController只支持基于等式的选择器(selector),例如selector(env=dev或environment!=qa)
- ReplicaSet还支持基于集合的选择器(selector),例如selector(version in (v1.0, v2.0))
如下创建一个replicaset的yaml配置文件replicaset_nginx.yml1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: nginx
labels:
tier: frontend
spec:
replicas: 3
selector:
matchLabels:
tier: frontend
template:
metadata:
name: nginx
labels:
tier: frontend
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
创建replicaset
1 | kubectl create -f replicaset_nginx.yml |
查看创建的replicaset1
2
3
4
5
6[root@ol75k8sn1 ~]# kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx 3 3 3 13m
[root@ol75k8sn1 ~]# kubectl get rs -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
nginx 3 3 3 13m nginx nginx tier=frontend
查看pods
1 | [root@ol75k8sn1 ~]# kubectl get pods -o wide |
删除一个pod1
2[root@ol75k8sn1 ~]# kubectl delete pod nginx-984tc
pod "nginx-984tc" deleted
再次查看,发现立马又新建了一个pod1
2
3
4
5[root@ol75k8sn1 ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-9726z 1/1 Running 0 19m 192.168.125.193 ol75k8sn3 <none> <none>
nginx-dpql6 1/1 Running 0 19m 192.168.43.71 ol75k8sn2 <none> <none>
nginx-szxjk 1/1 Running 0 15s 192.168.125.194 ol75k8sn3 <none> <none>
收缩replicaset
1 | [root@ol75k8sn1 ~]# kubectl scale rs nginx --replicas=2 |
扩张replicaset
1 | [root@ol75k8sn1 ~]# kubectl scale rs nginx --replicas=4 |
注意:
- replicaset一般也不会直接使用,而是通过deployment来管理使用
- 通过改变replicaset模板里面pod的镜像版本,可以实现滚动升级
Deployment
最常用的controller,用来部署pod,管理pod的副本也就是管理replicaset。
官方文档 Link
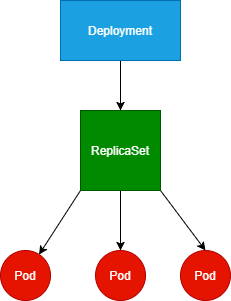
注意:
- 当用deployment来管理replicaset的时候,就不要再手动管理replicaset
如下一个deployment的配置文件的例子1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:v1.17.10
ports: 80
创建deployment1
2[root@ol75k8sn1 ~]# kubectl create -f deployment_nginx.yml
deployment.apps/nginx-deployment created
扩展1
kubectl scale deployment nginx-deployment --replicas=4
用service将deployment暴露给外网访问,具体见service章节1
kubectl expose deployment nginx-deployment --type=NodePort --port=80 --target-port=80
DaemonSet
每个node最多只能运行一个pod副本。
StatefulSet
用于保证pod的每个副本在整个生命周期中名称是不变的,而其他controller不提供这个功能。
Job
用于结束后就删除的pod。
Service
pod可以有多个副本,每个pod都有自己的IP,而pod会频繁的被销毁或创建,IP会发生变化,用IP来访问pod不现实。
Service定义了外界访问一组特定的pod的方式,service有自己的IP和端口,不管pod怎么变,service的IP和端口不变,Service为pod提供了负载均衡。
注意:
- 和Oracle的Service的概念有些类似
service有ClusterIP、NodePort、LoadBalancer几种类型
ClusterIP
通过kubectl expose为nginx-deployment这个deployment创建ClusterIP类型的service1
2
3
4
5
6[root@ol75k8sn1 ~]# kubectl expose deployment nginx-deployment
service/nginx-deployment exposed
[root@ol75k8sn1 ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 28d
nginx-deployment ClusterIP 10.101.174.40 <none> 80/TCP 12s
生成的service的IP是10.101.174.40,但这个IP只能用于K8S集群内部访问,也无法ping的通
NodePort
通过kubectl expose为nginx-deployment这个deployment创建NodePort类型的service1
kubectl expose deployment nginx-deployment --type=NodePort --port=80 --target-port=80
--type=NodePort指出创建的service类型是NodePort--port=80是service对外暴露的端口--target-port=80是deployment的端口
K8S自动将本机(或者说本节点)的32291端口,映射到service的80端口;端口的范围在30000到32767之间1
2
3
4[root@ol75k8sn1 ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 28d
nginx-deployment NodePort 10.99.119.252 <none> 80:32291/TCP 3s
之后就可以用任意K8S节点IP加端口来访问pod
如:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26C:\Users\1>curl 192.168.1.81:32291
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
LoadBalancer
通过kubectl expose为nginx-deployment这个deployment创建LoadBalancer类型的service1
kubectl expose deployment nginx-deployment --type=LoadBalancer --port=80 --target-port=80
注意:
- LoadBalance方式只能用于云K8S(如google的GCE,亚马逊的AWS,阿里云等),私有K8S无法使用,在私有K8S中创建LoadBalance类型的service,其
EXTERNAL-IP状态会一直是pending,也就是提示你一直获取不到EXTERNAL-IP- 云服务商会给LoadBalancer类型的service自动分配一个公网IP,并帮你做负载均衡
如下是在私有K8S上出错信息1
2
3
4
5
6[root@ol75k8sn1 ~]# kubectl expose deployment nginx-deployment --type=LoadBalancer --port=80 --target-port=80
service/nginx-deployment exposed
[root@ol75k8sn1 ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 28d
nginx-deployment LoadBalancer 10.102.236.210 <pending> 80:32338/TCP 25s
Ingress
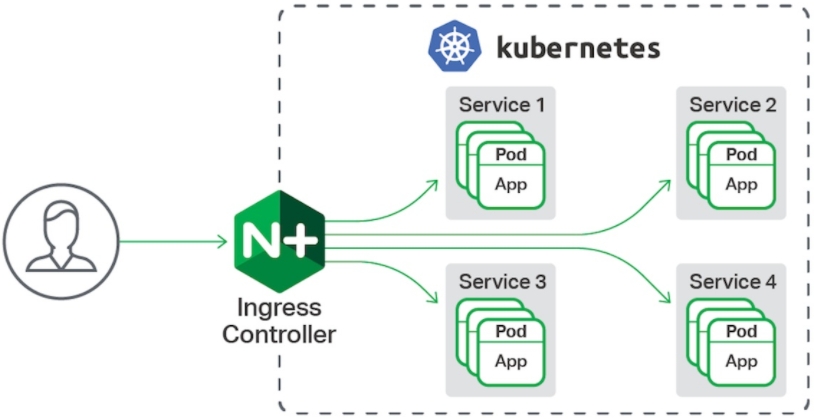
架构

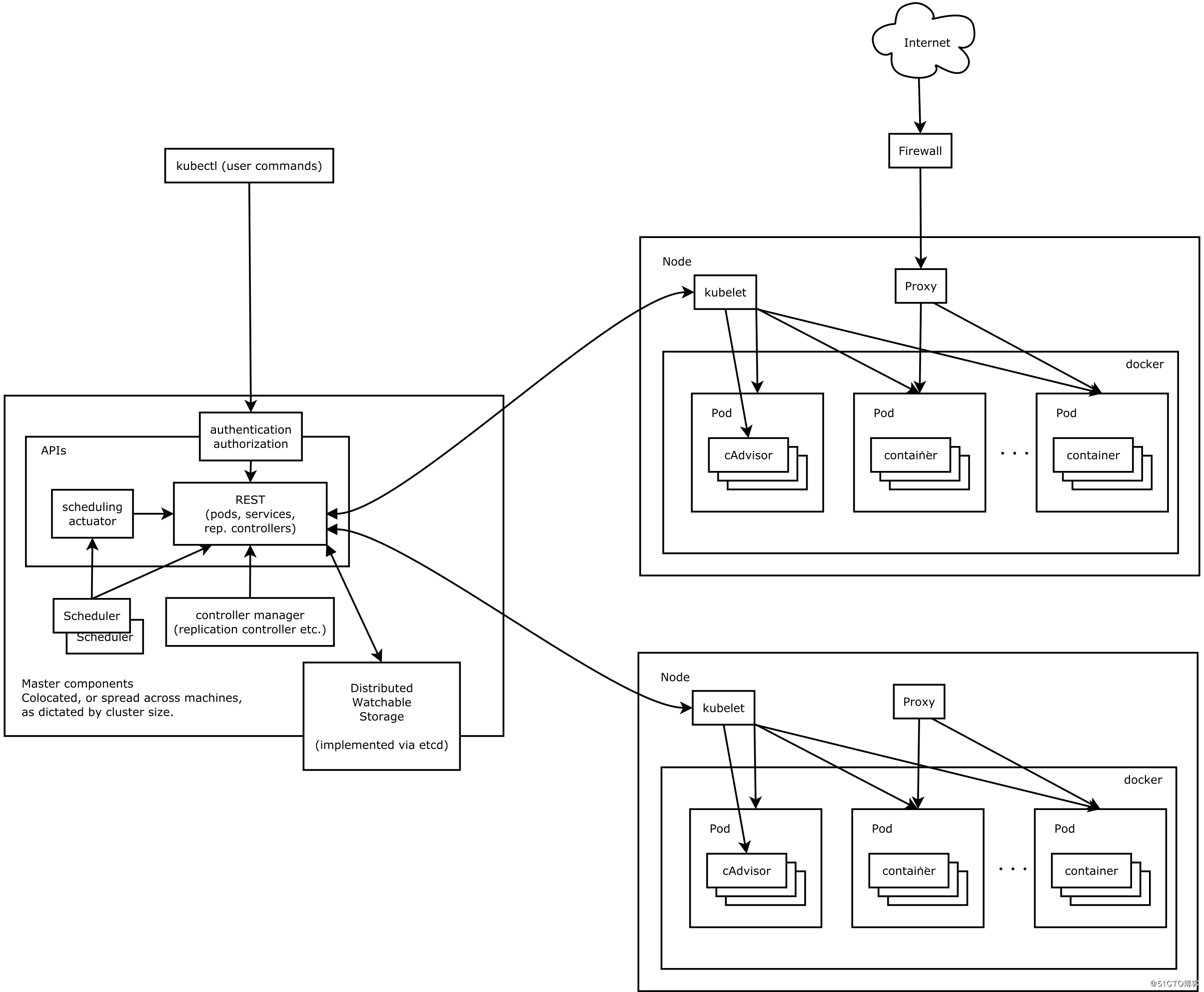
Master Node
etcd:保存整个集群的状态
API server:API接口,提供了操作资源的唯一接口;
包括:
- 授权
- 认证
- 访问控制
- API注册和发现等
Control Manager:用于维护集群的状态
比如:
- 故障检测
- 自动扩展
- 滚动更新
Scheduler:用于调度资源,比如将Pod调度到某个Node上
Node
Kubelet:用于管理容器的生命周期,同时也负责管理网络(CNI)和Volume存储(CVI)
Container Runtime:负责镜像的管理,以及容器和Pod的真正的运行
Proxy:为service提供cluster内部的服务发现和负载均衡
Add-on (TBD)
Docker基础 (TBD)
导入导出image
从本地repository中导出image为压缩包1
docker save -o superset.tar amancevice/superset:latest
导入到本地repository1
docker load -i superset.tar
注意:
- 也可以用
docker export和docker importsave/load是从image本身导出export/import是从container中导出,因此会带上用户在原始镜像基础上的修改
修改image的tag
有的时候我们拉下来的镜像是默认latest这个tag,不方便我们管理版本
用docker inspect命令侦测到镜像里的VERSION信息1
2
3
4
5[root@ol75k8sn1 ~]# docker inspect mysql|grep VERSION
"GOSU_VERSION=1.12",
"MYSQL_VERSION=8.0.20-1debian10"
"GOSU_VERSION=1.12",
"MYSQL_VERSION=8.0.20-1debian10"
使用docker tag命令修改镜像的tag,格式为镜像名:版本tag1
[root@ol75k8sn1 ~]# docker tag mysql mysql:v8.0.20-1debian10
改完后发现有两个同名,同image id,但tag不同的镜像1
2
3
4
5
6[root@ol75k8sn1 ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
mysql latest 94dff5fab37f 5 days ago 541MB
mysql v8.0.20-1debian10 94dff5fab37f 5 days ago 541MB
...
...
删掉tag为latest那个镜像1
2[root@ol75k8sn1 ~]# docker rmi mysql:latest
Untagged: mysql:latest
Kubernetes安装
Kubernetes的安装有好3种方式:通过minikube,kubeadm,通过二进制安装包手动安装
minikube用来部署单节点集群,主要用于测试
kubeadm是自动部署工具
建议初学者首次安装使用安装包手动安装一次,kubeadm自动部署隐藏了很多细节,不利于初学者理解
通过minikube部署测试环境
为了简化安装,这里我们会用到minikube
从kubernetes 1.3版本开始,kubernetes提供一个叫做minikube的测试工具,minikube可以很方便的在本机创建kubernetes的单节点集群
minikube的github链接 Link
安装kubectl
下载1
curl -LO https://storage.googleapis.com/kubernetes-release/release/`curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt`/bin/linux/amd64/kubectl
赋权限
1 | chmod +x ./kubectl |
挪到/usr/local/bin 下1
mv ./kubectl /usr/local/bin/kubectl
查看安装的kubectl的版本1
kubectl version
安装docker
通过yum安装容器运行时docker
1 | yum install docker |
设置docker的镜像仓库为阿里云镜像服务器
bash1
vi /etc/docker/daemon.json
其内容为
1 | { |
其中https://xxxxxxxx.mirror.aliyuncs.com为你通过阿里云获得的专属容器镜像加速地址
重启docker使配置生效1
2systemctl daemon-reload
systemctl restart docker
测试一下速度,尝试pull一个mysql镜像,非常快1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18[root@ol77-k8s bin]# docker pull mysql
Using default tag: latest
Trying to pull repository docker.io/library/mysql ...
latest: Pulling from docker.io/library/mysql
6d28e14ab8c8: Pull complete
dda15103a86a: Pull complete
55971d75ab8c: Pull complete
f1d4ea32020b: Pull complete
61420072af91: Pull complete
05c10e6ccca5: Pull complete
7e0306b13322: Pull complete
900b113c001e: Pull complete
06cd07c30bf4: Pull complete
df0d65aee5aa: Pull complete
53eeb6e0335c: Pull complete
6cf8f9563e97: Pull complete
Digest: sha256:f91e704ffa9f19b9a267d9321550a0772a1b64902226d739d3527fd6edbe3dfe
Status: Downloaded newer image for docker.io/mysql:latest
例:通过docker运行mysql
查看镜像仓库里面的image
1 | docker search mysql |
从镜像仓库拉取最新版的mysql
1 | docker pull mysql |
或者拉取某个固定版本的mysql(例如tag为5.7)1
docker pull mysql:5.7
查看本地可用的image
1 | docker images |
初次运行tag为5.7的mysql镜像
1 | docker run --name demo-mysql-5.7 -p 3310:3306 -e MYSQL_ROOT_PASSWORD=123456 -itd docker.io/mysql:5.7 |
--name demo-mysql-5.7:给容器起个名字-p 3310:3306:将本机端口3310映射到容器的端口3306-e MYSQL_ROOT_PASSWORD=123456:设置mysql的root密码-itd:i是交互式操作,t是一个终端,d指的是在后台运行
查看已启动的容器 (可以查到容器id,后面可以用名字也可以用容器id来操作)
1 | docker ps -a |
停止某运行的容器
1 | docker stop demo-mysql-5.7 |
或1
docker kill demo-mysql-5.7
重新启动容器1
docker start demo-mysql-5.7
交互式连接到docker的bash命令行(从而可以在docker内部执行命令)
1 | docker exec -it demo-mysql-5.7 bash |
连接到mysql(注意这里用-P指定的端口是外部端口,它会按照之前的设置被转换为docker内部的端口)
1 | root@2378f53e2bf7:/# mysql -P 3310 -u root -p |
连上mysql之后简单做一个查询
1 | mysql> select version(); |
查看mysql的状态
1 | mysql> status |
删除容器(删除前需要先关闭容器)1
docker rm demo-mysql-5.7
删除本地镜像(需要先删除运行的容器)1
docker rmi demo-mysql-5.7
查看容器的log,如下,查看最后100行log
1 | docker logs --tail=100 CONTAINER_ID |
安装minikube
下载和安装minikube1
2curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64 \
&& sudo install minikube-linux-amd64 /usr/local/bin/minikube
注意:
- 如果是运行在物理机上,需要在BIOS里面打开虚拟化
VT-x或AMD-v- 如果是运行在
vmware,由于不允许在虚拟层上再安装虚拟层,因此需要将vm-driver设为none- 如果是运行在
virtualbox上,需要将vm-driver设为virtualbox- 如果是运行在
KVM上,需要将vm-driver设为kvm2- 见文档 Link
默认minikube会分配2G内存,可以用下面的命令扩展到4G
1 | minikube config set memory 4096 |
启动minikube,同样用--registry-mirror定义使用阿里1
2
3minikube start --image-mirror-country cn \
--iso-url=https://kubernetes.oss-cn-hangzhou.aliyuncs.com/minikube/iso/minikube-v1.7.3.iso \
--registry-mirror=https://xxxxxxxx.mirror.aliyuncs.com
整个启动过程如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30[root@ol77-k8s bin]# minikube start --image-mirror-country cn \
> --iso-url=https://kubernetes.oss-cn-hangzhou.aliyuncs.com/minikube/iso/minikube-v1.7.3.iso \
> --registry-mirror=https://xxxxxxxx.mirror.aliyuncs.com
* minikube v1.7.3 on Oracle 7.7
* Using the none driver based on user configuration
* Running on localhost (CPUs=2, Memory=7965MB, Disk=83526MB) ...
* OS release is Oracle Linux Server 7.7
! VM is unable to access k8s.gcr.io, you may need to configure a proxy or set --image-repository
* Preparing Kubernetes v1.17.3 on Docker 1.13.1 ...
* Downloading kubectl v1.17.3
* Downloading kubeadm v1.17.3
* Downloading kubelet v1.17.3
* Launching Kubernetes ...
* Enabling addons: default-storageclass, storage-provisioner
* Configuring local host environment ...
*
! The 'none' driver provides limited isolation and may reduce system security and reliability.
! For more information, see:
- https://minikube.sigs.k8s.io/docs/reference/drivers/none/
*
! kubectl and minikube configuration will be stored in /root
! To use kubectl or minikube commands as your own user, you may need to relocate them. For example, to overwrite your own settings, run:
*
- sudo mv /root/.kube /root/.minikube $HOME
- sudo chown -R $USER $HOME/.kube $HOME/.minikube
*
* This can also be done automatically by setting the env var CHANGE_MINIKUBE_NONE_USER=true
* Waiting for cluster to come online ...
* Done! kubectl is now configured to use "minikube"
* For best results, install kubectl: https://kubernetes.io/docs/tasks/tools/install-kubectl/
之后就可以使用kubectl来操作kubernetes
打开kubernetes控制台
1 | [root@ol77-k8s Downloads]# minikube dashboard |
通过kubeadm部署集群
准备工作
环境
Oracle Linux 7.x
Kubernetes 1.18
配置节点环境
系统要求如下:
- 每个节点CPU至少2核,内存至少2G
- hostname,MAC地址,product_uuid每个节点必须不同
hostname在Oracle Linux 7.x中可以通过hostnamectl set-hostname设置
product_uuidke可以通过cat /sys/class/dmi/id/product_uuid查看
本次3个节点配置如下:
| IP | 角色 | CPU | 内存 | 主机名 |
| :——– | :——: | :——: | :——: | :——: |
| 192.168.1.81 | master | 2核 | 4G | ol75k8sn1 |
| 192.168.1.82 | master | 2核 | 4G | ol75k8sn2 |
| 192.168.1.83 | master | 2核 | 4G | ol75k8sn3 |
在/etc/hosts 中添加3个节点的IP解析1
2
3
4
5
6[root@ol75k8sn1 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.1.81 ol75k8sn1
192.168.1.82 ol75k8sn2
192.168.1.83 ol75k8sn3
检查端口是否被占用
K8S默认端口如下图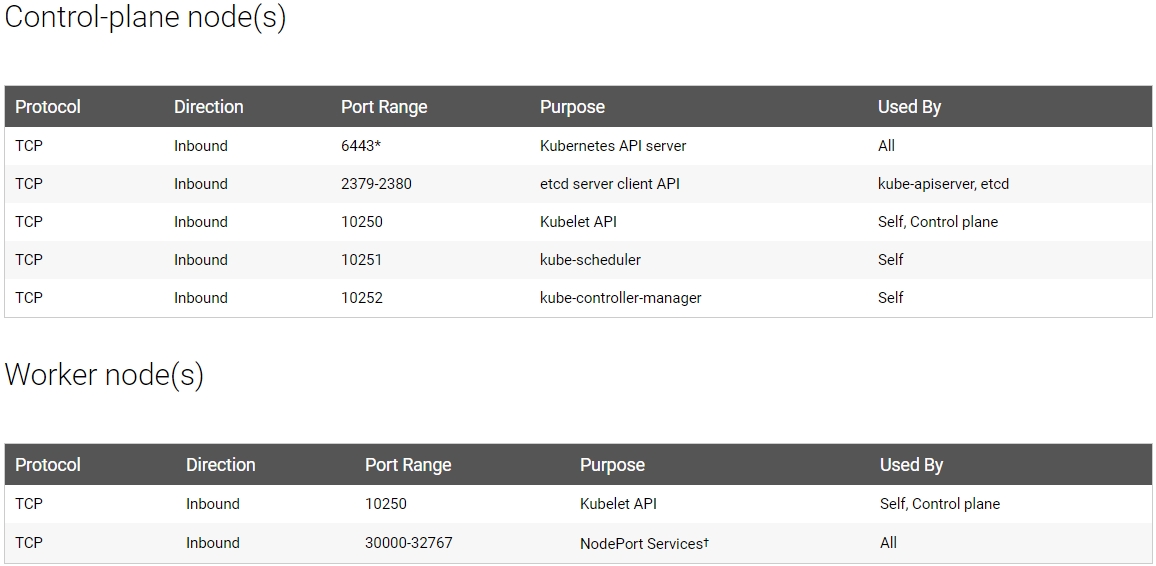
可以通过两种方法查看端口占用
方法一:
查看本机所有端口1
netstat -tunlp
查看特定端口1
netstat -tunlp | grep 8080
方法二:
查看特定端口1
lsof -i:8080
禁用swap
swap会降低K8S的性能
1 | swapoff -a |
注释掉/etc/fstab中的swap
1 | # |
无需重启
关闭selinux
修改配置文件/etc/selinux/config1
SELINUX=disabled
重启生效
关闭防火墙
1 | systemctl stop firewalld |
载入必要的内核模块
1 | modprobe br_netfilter |
配置国内yum源
添加阿里云的centos和epel源
见 GitPage Link
添加阿里云docker-ce的yum源1
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
添加阿里云K8S的yum源
1 | cat >> /etc/yum.repos.d/kubernetes.repo << EOF |
注意:
- 可以不做缓存
yum makecache,在移动网络下,时间较长
安装必须的软件包
1 | yum install -y screen conntrack ntp ipvsadm ipset jq iptables curl sysstat libseccomp wget vim net-tools git |
同步时间
通过网络ntp服务器同步一下各个节点的系统时间1
2yum install -y ntpdate
/usr/sbin/ntpdate ntp1.aliyun.com
如果是在实体机安装,时钟分硬件时钟和系统时钟
通过hwclock查看硬件时钟
1 | [root@labk8sn1 ~]# hwclock |
通过date查看系统时钟
1 | [root@labk8sn1 ~]# date |
将硬件时钟同步到系统时钟(以硬件时钟为准)
1 | hwclock --hctosys |
将系统时钟同步到硬件时钟(以系统时钟为准)
1 | hwclock --systohc |
注意:
- 在本例中,首先通过网络同步了系统时间,所以现在需要将系统时间同步给硬件时间
打开IP转发
Linux默认/proc/sys/net/ipv4/ip_forward的值是0,也就是禁止转发
1 | echo "1" > /proc/sys/net/ipv4/ip_forward |
注意:
- 重启网络或重启服务器后效果不再
因此,将echo "1" > /proc/sys/net/ipv4/ip_forward写入/etc/rc.d/rc.local保证开机时执行1
2vi /etc/rc.d/rc.local
echo "1" > /proc/sys/net/ipv4/ip_forward
安装iptables
1 | yum -y install iptables-services |
修改默认iptables的网桥设置
首先保证内核模块br_netfilter已经加载
默认下面这几个参数的值都是0,意味着iptables不对网桥(bridge)数据进行处理
1 | net.bridge.bridge-nf-call-ip6tables = 0 |
K8S要求这几个开关打开,iptables能看到和处理网桥数据1
2
3
4
5cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-arptables = 1
EOF
生效
1 | sysctl --system |
也可以把这几个参数放在/etc/sysctl.conf里面,然后通过/sbin/sysctl -p生效
日志持久化设置 (TBD)
1 | # 设置 rsyslogd 和 systemd journald |
安装容器运行时docker
docker-io和docker-engin是早期版本,版本号是1.x,Oracle Linux 7.x,Redhat Enterprise Linux 7.x和Centos 7.x默认安装的是docker-io,最新版是1.13。docker-ce是社区版,Ubuntu默认安装的是docker-ce,最新版本是19.03docker-ee是企业版。
列出可以安装的版本1
2
3
4[root@ol75k8sn1 ~]# yum list docker-ce
Loaded plugins: langpacks, ulninfo
Available Packages
docker-ce.x86_64 3:19.03.8-3.el7 docker-ce-stable
安装中如有如下报错信息,一般原因还是国内的源中包不全,一般添加阿里的centos和epel源之后都没有问题1
2
3
4Error: Package: 3:docker-ce-19.03.8-3.el7.x86_64 (docker-ce-stable)
Requires: container-selinux >= 2:2.74
Error: Package: containerd.io-1.2.13-3.1.el7.x86_64 (docker-ce-stable)
Requires: container-selinux >= 2:2.74
如果还是报错,需要手动到https://pkgs.org/download去下载安装
安装docker-ce
1 | yum install docker-ce |
设置开机自启动1
systemctl enable docker
启动docker1
systemctl start docker
安装kubernetes集群
在所有节点安装kubelet,kubeadm和kubectl1
yum install kubelet kubeadm kubectl
设置开机自启动kubelet1
systemctl enable kubelet
注意:
- 从这个时候开始,可以从node1克隆虚拟机为node2,node3以简化安装操作
kubelet的service现在启动会报错,这是正常情况,在下一节kubeadm init初始化之后,重启kubelet即可
初始化主节点
用下面的命令在主节点上初始化1
kubeadm init --image-repository=registry.aliyuncs.com/google_containers --kubernetes-version=v1.18.0 --pod-network-cidr=192.168.0.0/16
- –image-repository:指定仓库地址,这里指定阿里云的仓库
- –kubernetes-version:指定安装的kubernetes版本
- –pod-network-cidr:指定pod的地址取值网段
执行命令直到看到出现成功的信息
1 | Your Kubernetes control-plane has initialized successfully! |
根据上面提示,主节点上拷贝主节点的Kubernetes配置文件到用户目录下面,否则使用kubectl时会报错提示没有配置1
2
3mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
注意:
- 在子结点上,在
kubeadm join之前,不要拷贝生成$HOME/.kube/config,否则kubectl join会失败kubeadm init和kubeadm join之前,无需启动kubelet
安装网络插件
Calico或flannel都可以
配置Calico
Calico 是一款纯 Layer 3 的数据中心网络方案(不需要 Overlay 网络),Calico 好处是他已与各种云原生平台有良好的整合,而 Calico 在每一个节点利用 Linux Kernel 实现高效的 vRouter 来负责数据的转发,而当数据中心复杂度增加时,可以用 BGP route reflector 来达成
官方教程 Link
注意:
- Calico默认的IP段是
192.168.0.0/16,如果和你的需求不一致,请在master节点通过kubeadm init初始化时通过--pod-network-cidr更改
应用1
kubectl apply -f https://docs.projectcalico.org/manifests/calico.yaml
查看pod状态1
kubectl get pods --all-namespaces
所有的pod状态都应该是running1
2
3
4
5
6
7
8[root@ol75k8sn1 ~]# kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-6fcbbfb6fb-hxrqh 1/1 Running 0 9d
kube-system calico-node-dk9gq 1/1 Running 0 9d
kube-system calico-node-qw57c 1/1 Running 0 21m
kube-system calico-node-slcqv 1/1 Running 0 21m
...
...
配置Flannel(Calico和Flannel二选一)
flannel只需要在Node节点安装,Master节点无需安装
docker import flannel-v0.11.0-linux-amd64.tar quay.io/coreos/flannel:v0.11.0-arm64
kubectl apply -f kube-flannel.yml
加入子节点
将其余两个节点加入1
2kubeadm join 192.168.1.81:6443 --token n556jt.wnkqsc536gzw8xvk \
--discovery-token-ca-cert-hash sha256:819a6cab80a0c617f972a9e04c71d1fbff92c383ce66d2e6a13f2106c7e960ad
查看集群的状态,可以看到status和roles还不正常,这主要是因为还没有安装网络插件1
2
3
4
5[root@ol75k8sn1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
ol75k8sn1 NotReady master 3h40m v1.18.2
ol75k8sn2 NotReady <none> 7m48s v1.18.2
ol75k8sn3 NotReady <none> 8m13s v1.18.2
Toubleshooting:Token失效后如何加入子节点
在1.8版之后,默认生成的 token 有效期只有 24 小时
在master节点上重新生成token1
2
3[root@ol75k8sn1 ~]# kubeadm token create
W0505 18:33:08.907564 25966 configset.go:202] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io]
fo2k3z.mpfllk3gextyuqoa
获取 CA 证书 sha256 编码的 hash 值1
2[root@ol75k8sn1 ~]# openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'
be840f62afba37facbdf3e9d9aa487c3b65bf7c06fc7dce65c32662c4a1cd41d
根据上面的结果,重新生成kubeadm join语句1
2kubeadm join 192.168.1.81:6443 --token fo2k3z.mpfllk3gextyuqoa \
--discovery-token-ca-cert-hash sha256:be840f62afba37facbdf3e9d9aa487c3b65bf7c06fc7dce65c32662c4a1cd41d
扫尾排错工作
CASE 1
查看节点状态都是Ready1
2
3
4
5[root@ol75k8sn1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
ol75k8sn1 Ready master 9d v1.18.2
ol75k8sn2 Ready <none> 6h22m v1.18.2
ol75k8sn3 Ready <none> 6h22m v1.18.2
但kubelet虽然是running状态的log依然报错1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23[root@ol75k8sn1 ~]# systemctl status kubelet
● kubelet.service - kubelet: The Kubernetes Node Agent
Loaded: loaded (/usr/lib/systemd/system/kubelet.service; enabled; vendor preset: disabled)
Drop-In: /usr/lib/systemd/system/kubelet.service.d
└─10-kubeadm.conf
Active: active (running) since Wed 2020-05-06 01:10:12 CST; 17min ago
Docs: https://kubernetes.io/docs/
Main PID: 735 (kubelet)
Memory: 112.3M
CGroup: /system.slice/kubelet.service
└─735 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubern...
May 06 01:26:27 ol75k8sn1 kubelet[735]: W0506 01:26:27.945469 735 qos_container_manager_linux.go:138] [Contain...: pids
May 06 01:26:30 ol75k8sn1 kubelet[735]: E0506 01:26:30.167506 735 summary_sys_containers.go:47] Failed to get system...
May 06 01:26:40 ol75k8sn1 kubelet[735]: E0506 01:26:40.298518 735 summary_sys_containers.go:47] Failed to get system...
May 06 01:26:50 ol75k8sn1 kubelet[735]: E0506 01:26:50.327160 735 summary_sys_containers.go:47] Failed to get system...
May 06 01:27:00 ol75k8sn1 kubelet[735]: E0506 01:27:00.347778 735 summary_sys_containers.go:47] Failed to get system...
May 06 01:27:10 ol75k8sn1 kubelet[735]: E0506 01:27:10.368074 735 summary_sys_containers.go:47] Failed to get system...
May 06 01:27:20 ol75k8sn1 kubelet[735]: E0506 01:27:20.388551 735 summary_sys_containers.go:47] Failed to get system...
May 06 01:27:27 ol75k8sn1 kubelet[735]: E0506 01:27:27.946584 735 qos_container_manager_linux.go:328] [Contain...ration
May 06 01:27:27 ol75k8sn1 kubelet[735]: W0506 01:27:27.946605 735 qos_container_manager_linux.go:138] [Contain...: pids
May 06 01:27:30 ol75k8sn1 kubelet[735]: E0506 01:27:30.411942 735 summary_sys_containers.go:47] Failed to get system...
Hint: Some lines were ellipsized, use -l to show in full.
根据提示用systemctl status kubelet -l来查看完整的报错信息,如下1
2May 06 01:23:27 ol75k8sn1 kubelet[735]: W0506 01:23:27.935354 735 qos_container_manager_linux.go:138] [ContainerManager] Failed to reserve QoS requests: failed to set supported cgroup subsystems for cgroup [kubepods burstable]: failed to find subsystem mount for required subsystem: pids
May 06 01:23:29 ol75k8sn1 kubelet[735]: E0506 01:23:29.752777 735 summary_sys_containers.go:47] Failed to get system container stats for "/system.slice/docker.service": failed to get cgroup stats for "/system.slice/docker.service": failed to get container info for "/system.slice/docker.service": unknown container "/system.slice/docker.service"
在所有节点修改kubelet服务的配置文件/usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf1
vi /usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf
在最后一行ExecStart最后添加--feature-gates SupportPodPidsLimit=false --feature-gates SupportNodePidsLimit=false
修改前
1 | # Note: This dropin only works with kubeadm and kubelet v1.11+ |
修改后
1 | # Note: This dropin only works with kubeadm and kubelet v1.11+ |
重启所有节点
CASE 2
经过CASE 1排错,主节点已经没有问题,但子节点依然报错
1 | May 06 02:17:19 ol75k8sn3 kubelet[740]: E0506 02:17:19.298801 740 summary_sys_containers.go:47] Failed to get system container stats for "/system.slice/docker.service": failed to get cgroup stats for "/system.slice/docker.service": failed to get container info for "/system.slice/docker.service": unknown container "/system.slice/docker.service" |
继续在所有子节点修改kubelet服务的配置文件/usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf
1 | vi /usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf |
添加环境参数Environment="KUBELET_CGROUP_ARGS=--cgroup-driver=cgroupfs --runtime-cgroups=/systemd/system.slice --kubelet-cgroups=/systemd/system.slice"
修改前1
2
3
4
5
6
7
8
9
10
11# Note: This dropin only works with kubeadm and kubelet v1.11+
[Service]
Environment="KUBELET_KUBECONFIG_ARGS=--bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf"
Environment="KUBELET_CONFIG_ARGS=--config=/var/lib/kubelet/config.yaml"
# This is a file that "kubeadm init" and "kubeadm join" generates at runtime, populating the KUBELET_KUBEADM_ARGS variable dynamically
EnvironmentFile=-/var/lib/kubelet/kubeadm-flags.env
# This is a file that the user can use for overrides of the kubelet args as a last resort. Preferably, the user should use
# the .NodeRegistration.KubeletExtraArgs object in the configuration files instead. KUBELET_EXTRA_ARGS should be sourced from this file.
EnvironmentFile=-/etc/sysconfig/kubelet
ExecStart=
ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS --feature-gates SupportPodPidsLimit=false --feature-gates SupportNodePidsLimit=false
修改后
1 | # Note: This dropin only works with kubeadm and kubelet v1.11+ |
重启子节点的kubelet服务
再次查看kubelet的log,确认没有Error信息
Dashboard部署(TBD)
通过二进制安装包部署集群
安装Kubernetes集群过程中可能遇到的问题 (TBD)
如何修改地址范围
k8s 中如何修改 pod-network-cidr 地址范围
打开下面的2个配置,将 10.244.0.0/16 改为 192.168.0.0/16
1)kubectl -n kube-system edit cm kubeadm-config
2)vim /etc/kubernetes/manifests/kube-scheduler.yaml
通过 kubectl cluster-info dump | grep -m 1 cluster-cidr 命令可以检查配置是否生效
配置
默认情况下,master节点不应该参与pod的调度,但可以通过设置改变
注意:
- 让master节点参与pod调度有可能会因为master节点资源不足导致K8S集群不稳定
kubernetes是通过的taint(污点)来决定调度规则的
存储卷
Troubleshooting
1. 强制删除pod
一般删除pod都是通过kubectl delete pod来删的
有的时候,删除pod后一直是Terminating状态,无法继续,如下1
2
3[root@labk8sn1 ~]# kubectl get pods --all-namespaces -o wide
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kube-system coredns-7ff77c879f-s5jc5 0/1 Terminating 0 38m 192.168.102.80 labk8sn2 <none> <none>
可以通过kubectl delete pods <pod> --grace-period=0 --force来强制删除1
kubectl delete pods calico-kube-controllers-789f6df884-dvpk8 --grace-period=0 --force -n kube-system
2. 重置kubernetes
有的时候安装失败,或网络插件有问题,或换IP,或者其他一些场景,需要重新kubeadm init和kubeadm join,这种情况下,运行以下命令重置kubenetes1
2
3
4
5
6# 重置kubeadm
# 清空iptables规则
# 重启
kubeadm reset -f
iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
reboot
重启后需要删除之前kubeadm生成的配置文件
1 | rm -rf $HOME/.kube |
注意:
- 重置后,再次
kubeadm init或kubeadm join都无需联网
3. 端口占用
重置之后,再次kubeadm join,报错如下1
[ERROR Port-10250]: Port 10250 is in use
用lsof -i:10250发现就是kubelet在占用
再次kubeadm reset并重启即可
4. 在reset之后需要清理旧配置文件
报错如下1
2[root@labk8sn1 default]# kubectl get nodes
Unable to connect to the server: x509: certificate signed by unknown authority (possibly because of "crypto/rsa: verification error" while trying to verify candidate authority certificate "kubernetes")
这种情况一般出现在重置之后,由于没有删除旧的配置文件夹$HOME/.kube,导致报错
删除旧的配置文件夹1
rm -rf $HOME/.kube
再按照kubeadm init提示信息里面重新拷贝一份新的即可
1 | mkdir -p $HOME/.kube |
5. cgroup driver不匹配
在我们kubeadm init或kubeadm join运行时,会发现有如下提示信息,这不是个错误,只是报警1
2[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/
error execution phase preflight: [preflight] Some fatal errors occurred:
注意:
- docker的cgroup driver和K8S的cgroup driver必须一致
这个报警信息的主要原因是docker的默认cgroup driver是cgroupfs,K8S会侦测到docker的cgroup driver,并将自己的cgroup driver设置为cgroupfs;但提示信息里面推荐用systemd
但尝试换为systemd没有成功
注意以下操作没有成功
尝试把cgroupfs改为systemd
修改docker
1 | cat > /etc/docker/daemon.json <<EOF |
1 | mkdir -p /etc/systemd/system/docker.service.d |
重启docker
1 | systemctl daemon-reload |
修改K8S
1 | vi /usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf |
修改参数如下1
Environment="KUBELET_CGROUP_ARGS=--cgroup-driver=systemd --runtime-cgroups=/systemd/system.slice --kubelet-cgroups=/systemd/system.slice"
重启kubelet1
2systemctl daemon-reload
systemctl restart kubelet
注意:
- 如果需要修改
systemd,以上systemd替换为cgroupfs即可
6. Calico BIRD is not ready: BGP not established
现象还包括某个calico-node状态一直不正常,保持在0/11
kube-system calico-node-dpln6 0/1 Running 0 26m
这个问题主要是Calico自动匹配的网卡不对导致(比如服务器有多个网卡,Calico自动匹配第一个网卡,但这个网卡并不对),修改下载下来的配置文件calico.yaml
搜索name: IP
在它上面加入2行,告知用到网卡是哪个,比如,我指定的是绑定网卡bond0
1 | - name: IP_AUTODETECTION_METHOD |
保存后应用修改
1 | kubectl apply -f calico.yaml |
注意:
- 实在解决不了只能重置,重置一般能解决问题,之前我就是不管怎么改都不行,重置后解决
7. Orphaned pod found
报错如下1
Jan 21 16:45:44 localhost kubelet[1277]: E0121 16:45:44.079748 1277 kubelet_volumes.go:128] Orphaned pod "86d60ee9-9fae-11e8-8cfc-525400290b20" found, but volume paths are still present on disk. : There were a total of 1 errors similar to this. Turn up verbosity to see them.
原因主要时删除pod后,K8S没有清理干净,还能找到残留的文件
根据提示信息,到/var/lib/kubelet/pods/下将于报错信息对应的一长串数字命名的文件夹删掉即可
应用部署
Node-Red
docker部署
拉取最新的nodered 1.04的镜像1
docker pull nodered/node-red:1.0.4
运行容器1
docker run -it -p 1880:1880 -v /data/nodered:/data -e TZ=Asia/Shanghai --name nodered -d nodered/node-red:1.0.4
-p 1880:1880将本机端口1880映射为容器端口1880-v /data/nodered:/data将本机目录/data/nodered映射为容器内目录/data,容器内的默认目录就是/data-e TZ=Asia/Shanghai设置时区--name nodered生成的容器命名为nodered-d nodered/node-red:1.0.4部署的本地镜像是nodered/node-red:1.0.4
注意:
- 在虚拟机上创建本地目录时,例如本例中是
/data/nodered,需要将其读写权限设为777,否则报错
K8S部署
创建名为deployment_nodered.yml的配置文件1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28apiVersion: apps/v1
kind: Deployment
metadata:
name: nodered-deployment
labels:
app: nodered
spec:
replicas: 1
selector:
matchLabels:
app: nodered
template:
metadata:
labels:
app: nodered
spec:
containers:
- image: nodered/node-red:1.0.4
name: nodered
ports:
- containerPort: 1880
volumeMounts:
- name: nodered-volume-01
mountPath: /data
volumes:
- name: nodered-volume-01
hostPath:
path: /data/nodered/nodered01
节点上本机目录为/data/nodered/nodered01,赋予777权限
创建
1 | kubectl create -f deployment_nodered.yml |
通过service暴露端口
1 | kubectl expose deployment nodered-deployment --type=NodePort --port=1880 --target-port=1880 |
如下暴露出来的端口是309471
2
3
4[root@labk8sn1 ~]# kubectl get svc -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2d3h <none>
nodered-deployment NodePort 10.102.77.22 <none> 1880:30947/TCP 12s app=nodered
通过任意节点IP加如上端口访问
MySQL
superset
官方github Link
运行superset1
docker run --name superset -itd -p 8088:8088 -v /data/superset/config:/etc/superset -v /data/superset/sqllite:/var/lib/superset amancevice/superset
-v:挂载目录,对于superset来说,配置文件目录/etc/superset或者/home/superset 都可以,只要映射一个就行;本例中将本机的/data/superset映射为容器的/home/superset;数据文件目录在容器的/var/lib/superset下
注意:
-v可以多次使用来挂载多个目录- 本机目录需要777权限
初始化数据库,会提示创建admin user
1 | docker exec -it superset superset-init |
之后就可以通过http://IP:8088的方式来打开superset的UI
容器如果需要版本升级,见github
Helm
私有K8S集群创建LoadBalance服务(TBD)
通过metallb为私有的Kebernetes集群创建Load Balance服务
metallb Github link
metallb会从你给定的IP池中选一个作为service的external IP给到deployment
附件
http://docs.kubernetes.org.cn/227.html
History
v1.0,2020.02.15~2020.05.31,初始版本
本文作者 : Shen Peng
原文链接 : http://yoursite.com/2020/02/15/Kubernetes-K8S/
版权声明 : 本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明出处!
知识 & 情怀 | 二者兼得

